Dec 7, 2016
A new visualization technique from the Georgia Institute of Technology could help users end the time-consuming habit of continually checking social media streams and endless updates. Where users might now commit minutes or hours on a single topic spanning thousands of posts, the Georgia Tech technique produces a single compiled social post that reads almost like a headline. Users are able to immediately understand the conversation and interact with the words and ideas that are being talked about the most, whether they are from an election, major sporting event, or latest product release.
“The technique seeks a balance between showing the most frequent words and preserving sentence structure,” says lead researcher Mengdie Hu, a Ph.D. student in Human-Centered Computing. “It gives people a high-level overview of the most common expressions in a document collection and how they are connected to each other.”
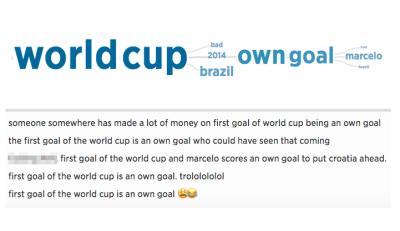
Implemented in a web browser, the visualization tool, called SentenTree (short for Sentence Tree), has been used to take almost a quarter of a million tweets shared in a 15-minute window of time during the 2014 World Cup and filter the conversation. The resulting single 100-word social post revealed that Brazil scored a goal in its own net, putting them down 0-1 in their match against Croatia. In the example post, “World Cup” and “own goal” are larger than other words, signaling that they appear more frequently. In the middle of and connecting these two phrases are “2014,” “bad,” and “Brazil,” which together give an idea of the larger social conversation. If users want more context, SentenTree allows them to hover over any word and drill down to see more details, including the number of times the phrases appear along with the original tweets.
“Even if you don’t know anything about soccer, there are visual cues to help users connect the concepts and play with the data,” Hu says. “The central idea behind SentenTree is to take a large social media dataset, find the most frequent sequences of words, and build a visualization out of them that mirrors the real-time conversation.”
The researchers say that while there are numerous analytical tools for social media data that highlight concept relationships, topical changes, or physical locations, less common are tools that visualize the actual text content itself. SentenTree is designed to remedy this by consolidating, finding patterns in, and delivering useful content from many sources into one simple interactive view.
The algorithms developed for SentenTree analyze the unstructured text data — developing a baseline sequential pattern of similar ideas and sentiments, all the while keeping a sentence-like structure — then incrementally add new words that build on the pattern as the algorithms search the text and kick out duplicate language. This allows the visualization to be a concise, readable representation of multiple thousands of threads. The visualization is even modified in length, based on the size of the screen, and is usually between 100-200 words.
“There is an unwieldy volume of unstructured text on the web that continues to grow explosively,” says John Stasko, professor of Interactive Computing at Georgia Tech and part of the research team. “Social media text includes rich information on the public’s interests and opinions, and we hope this technique can start to uncover important patterns and ideas that exist in this data.”
The Georgia Tech researchers are developing their tool to allow for a broader cross section of ideas to surface on the social web – anywhere from YouTube to Facebook to Reddit – instead of simply relying on what social media influencers, such as celebrities or prominent public figures, post on their channels.
SentenTree eventually will be available online for users to upload their own datasets to visualize. The work, presented in October at the IEEE Vis 2016 conference in Baltimore, Maryland, is published in the paper “Visualizing Social Media Content with SentenTree.”
###
This research is supported in part by the DARPA XDATA program and the National Science Foundation, Award IIS-1320537. The views and opinions expressed are those of the authors and do not necessarily represent the funding partners.
Related Media
-
Sententree Visualization - Information Interfaces Group
-
John Stasko
-
Mengdie Hu